最近看到@lchiffon写的wordcloud2,比wordcloud使用更简单,效果也更炫酷更灵活。于是想画一个WISE老师发表英文论文的关键词的词云。本文的步骤包括数据抓取和绘制词云两个步骤。
0. 准备
0.1 安装wordcloud2
wordcloud2首次运行前需要从作者的github下载安装,运行下面的代码:
1
| devtools::install_github("lchiffon/wordcloud2")
|
0.2 载入要用的包:
1 2 3 4 5 6 7
| library(RCurl) library(XML) library(stringr) library(plyr) library(dplyr) library(wordcloud2) library(tm)
|
Rcurl和XML用于网页的抓取,stringr用于抓取文本的处理和提取plyr和dplyr用于数据变形和处理wordcloud2则用于词云的绘制
1. 抓取论文信息
王亚南经济研究院(WISE)成立于2005年,是厦门大学一个实体性的经济学教育科研机构,不太长的时间内,成为亚太地区和中国一流的、与国际接轨的现代经济学教育和研究机构。
WISE将所有老师公开发表的论文放在 http://121.192.176.75/index.php?ser_id=2这个网站上,其中英文期刊有180篇, 中文有60余篇。我们这次为了绘制词云的美观,只选去其中英文期刊的关键词信息。
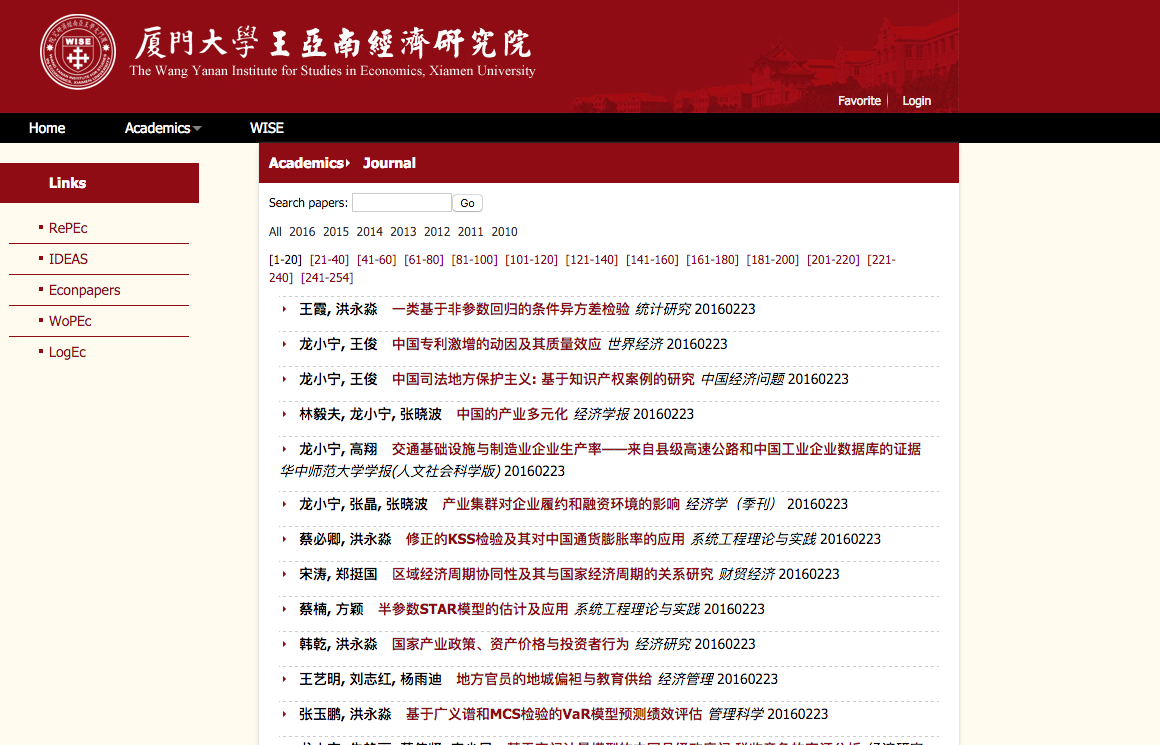
1.1 获得分页网址
网站将250多个论文条目每20条放置一页,每个分页通过网址体现出来,http://121.192.176.75/index.php?ser_id=2&search=&year=&os=<数字>, <数字位置>为20的倍数, 总共有13页。下面的代码生成没个分页的网址。
1 2
| # 获得论文的每一个分页 pageLinks <- str_c("http://121.192.176.75/index.php?ser_id=2&search=&year=&os=",seq(0, 240, 20))
|
1.2 获得每篇论文的链接
getHTMLLinks是Rcurl内置的一个函数,这个函数可以获得某个页面上所有的链接:
- 对上面生成的页面网址应用
getHTMLLinks函数, 就可以获得这些分页上的所有的网址;
- 对抓取的网址匹配
"\\?ser_id=2&p_id=\\d+"获得符合条件的论文的链接;
- 补齐网址。
代码如下:
1 2 3 4 5 6
| paperlinks <- lapply(pageLinks, getHTMLLinks)%>% unlist()%>% str_extract("\\?ser_id=2&p_id=\\d+")%>% na.omit()%>% str_c("http://121.192.176.75/index.php",.) head(paperlinks)
|
1 2 3 4 5 6
| ## [1] "http://121.192.176.75/index.php?ser_id=2&p_id=2329" ## [2] "http://121.192.176.75/index.php?ser_id=2&p_id=2322" ## [3] "http://121.192.176.75/index.php?ser_id=2&p_id=2333" ## [4] "http://121.192.176.75/index.php?ser_id=2&p_id=2338" ## [5] "http://121.192.176.75/index.php?ser_id=2&p_id=2332" ## [6] "http://121.192.176.75/index.php?ser_id=2&p_id=2321"
|
1.3 抓取论文信息
我们使用Rcurl包内的xpathSApply函数, 通过匹配Xpath定位我们需要抓取的内容在网页的位置进行抓取(不懂Xpath,可以参考w3schools提供的一个系列教程http://www.w3schools.com/xsl/xpath_intro.asp)。
getPaperInfo是抓取单条论文信息的函数,返回包含author, title,journal,keyWords, paperlink,fullTextLink, updatedDate的data.frame
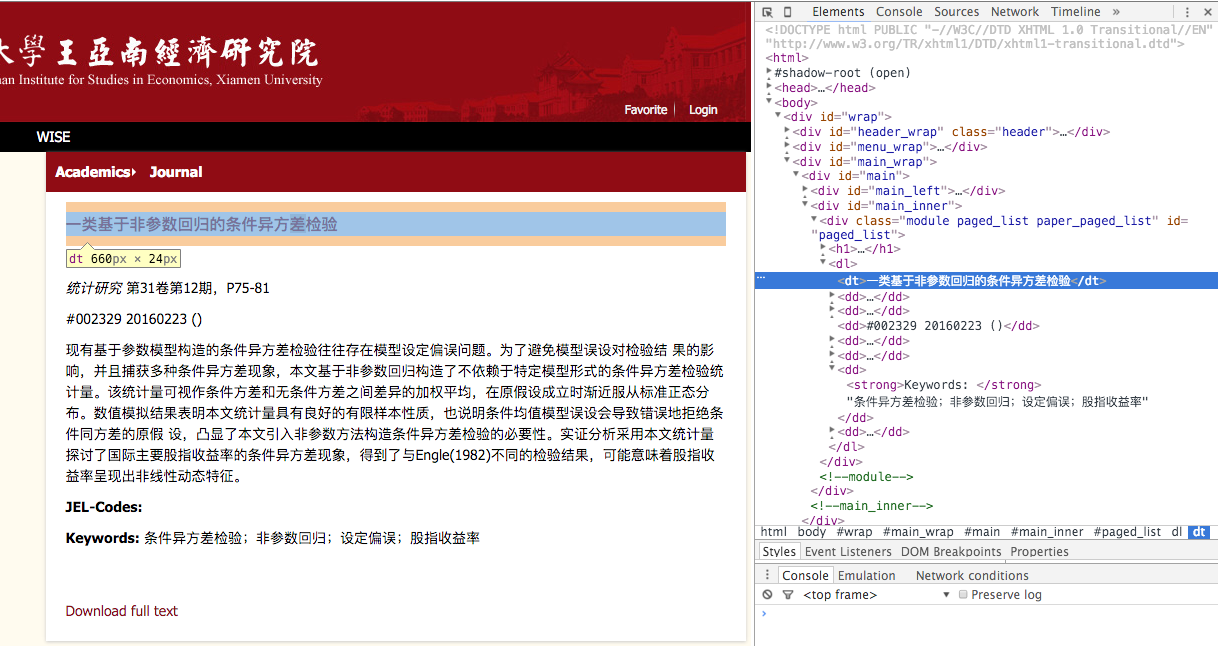
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
| # Function to scrap getPaperInfo <- function(paperlink){ page_parse <- htmlParse(paperlink,encoding = "utf-8") # Get author name author <- xpathSApply(page_parse,'//*[@id="paged_list"]/dl/dd[1]/strong',xmlValue) # insert & between diff names author <- str_replace(author, ',','\\&') # paper title title <- xpathSApply(page_parse,'//*[@id="paged_list"]/dl/dt', xmlValue) # paper url journal <- xpathSApply(page_parse,'//*[@id="paged_list"]/dl/dd[2]/i', xmlValue) # File name include authoe title journal keyWords <- xpathSApply(page_parse,'//*[@id="paged_list"]/dl/dd[6]/text()', xmlValue) keyWords <- ifelse(length(keyWords)==0, NA, keyWords) fullTextLink <- getHTMLLinks(page_parse)%>% str_extract(".+\\.pdf")%>% na.omit() fullTextLink <- ifelse(length(fullTextLink)==0,NA, str_c("http://121.192.176.75",fullTextLink)) updatedDate <- xpathSApply(page_parse,'//*[@id="paged_list"]/dl/dd[3]', xmlValue)%>% str_extract("20\\d{6}") paperInfo <- data.frame(author, title,journal,keyWords, paperlink,fullTextLink, updatedDate) return(paperInfo) } getPaperInfo(paperlinks[10])
|
1 2 3 4 5 6 7 8
| # author title journal keyWords #1 韩乾& 洪永淼 国家产业政策、资产价格与投资者行为 经济研究 产业政策,过时信息,过度反应 # paperlink # http://121.192.176.75/index.php?ser_id=2&p_id=2327 # fullTextLink #1 http://121.192.176.75/repec/upload/201602231742217864.pdf #updatedDate # 20160223
|
我们对所有的paperlinks应用getPaperInfo就会获得所有的论文的信息
1 2
| papers.df <- lapply(paperlinks, getPaperInfo)%>% do.call("rbind",.)
|
2. 绘制词云
本部分我们对WISE 老师发表的英文期刊的关键词绘制词云。
2.1 WISE老师喜欢发什么期刊?
首先我们通过正则条件将英文期刊发表的论文的信息提取出来,
1 2 3 4 5
| papers.en <- papers.df[str_detect(papers.df$journal,"[A-Za-z]"),] papers.en$journal <- trimws(papers.en$journal) journalRank <- table(papers.en$journal)%>%as.data.frame()%>%arrange(-Freq) names(journalRank) <- c("journal","Freq") head(journalRank)
|
1 2 3 4 5 6 7
| # journal Freq # 1 Journal of Econometrics 25 # 2 China Economic Review 16 # 3 Econometric Theory 8 # 4 Journal of the American Statistical Association 7 # 5 Econometric Reviews 4 # 6 Economics Letters 3
|
从上面WISE老师发表论文最多的六个期刊可以看出来,WISE老师发表的论文还是以计量统计为主, 发表论文的质量也是蛮高的, 计量经济学field第一的期刊JOE,竟然发了25篇。。。
2.2 WISE的老师都在研究啥?
2.2.1 计算词频
下面我们想看看WISE老师发表的论文都在说啥吧。我们下面统计下所有的论文关键词的词频。
下面的代码把所有的关键词放在一起,并对英文单词的大小写, 标点,空格, 和停止词(比如and, a, um)处理,然后统计了各个单词的出现频率。
1 2 3 4 5 6 7 8 9 10 11 12
| keyWords <- str_c(na.omit(papers.en$keyWords), collapse = " ") keyWords_source <- VectorSource(keyWords) wordMatrix <- Corpus(keyWords_source)%>% tm_map(content_transformer(tolower))%>% tm_map(removePunctuation)%>% tm_map(stripWhitespace)%>% tm_map(removeWords, stopwords("english"))%>% DocumentTermMatrix()%>%as.matrix()%>%t()%>% as.data.frame() wordMatrix$Term <- rownames(wordMatrix) names(wordMatrix) <- c("Freq","Term") termFreq <- select(wordMatrix, Term, Freq)
|
2.3 绘制词云
###2.3.1 使用wordcloud2绘制词云
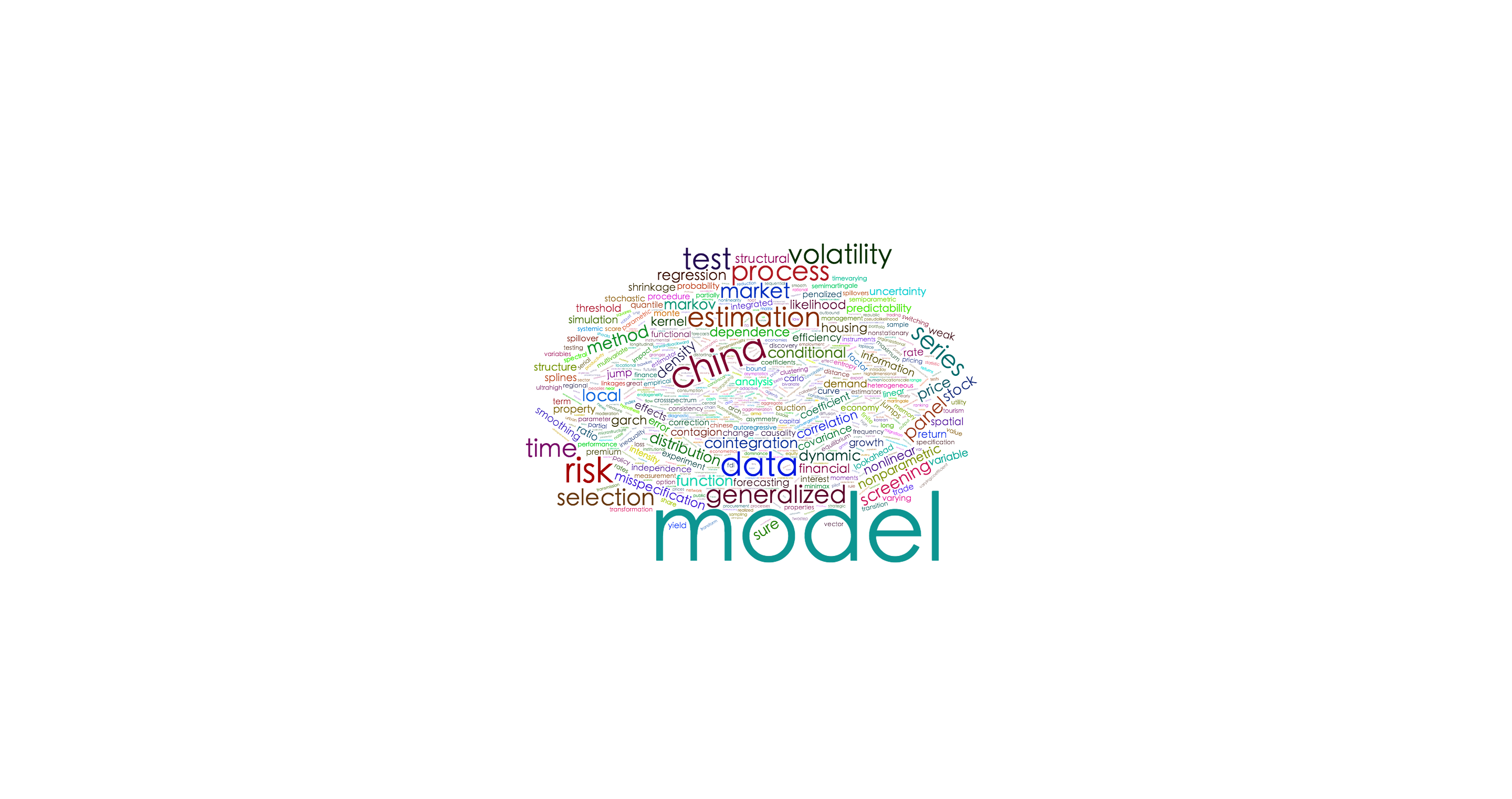
我们可以通过修改size, color, shape等参数修改字体大小, 颜色,以及词云形状。
1
| wordcloud2(termFreq, size = 1,shape = 'star')
|
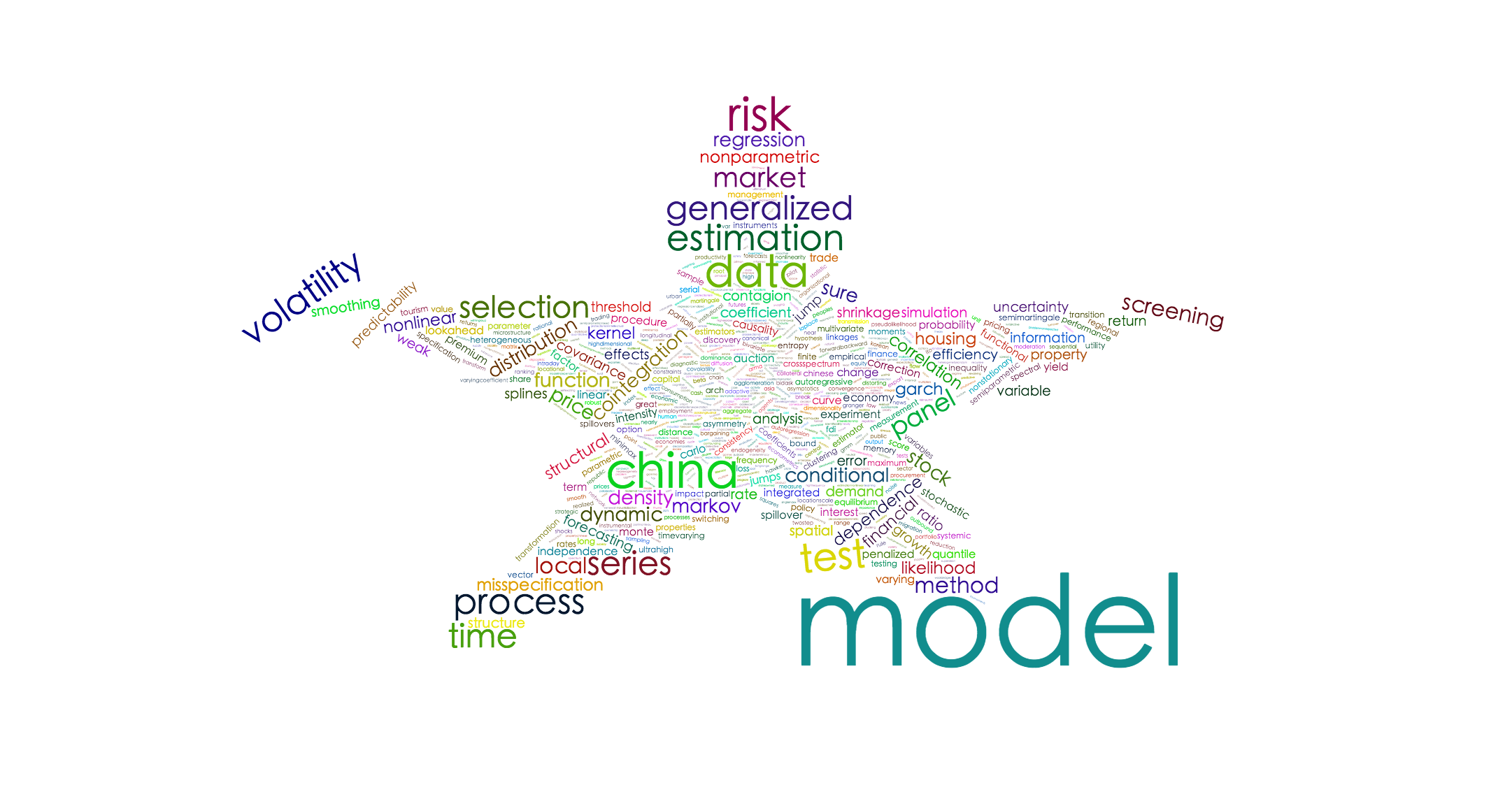
1 2
| wordcloud2(termFreq, size = 2, minRotation = -pi/6, maxRotation = -pi/6, rotateRatio = 1)
|
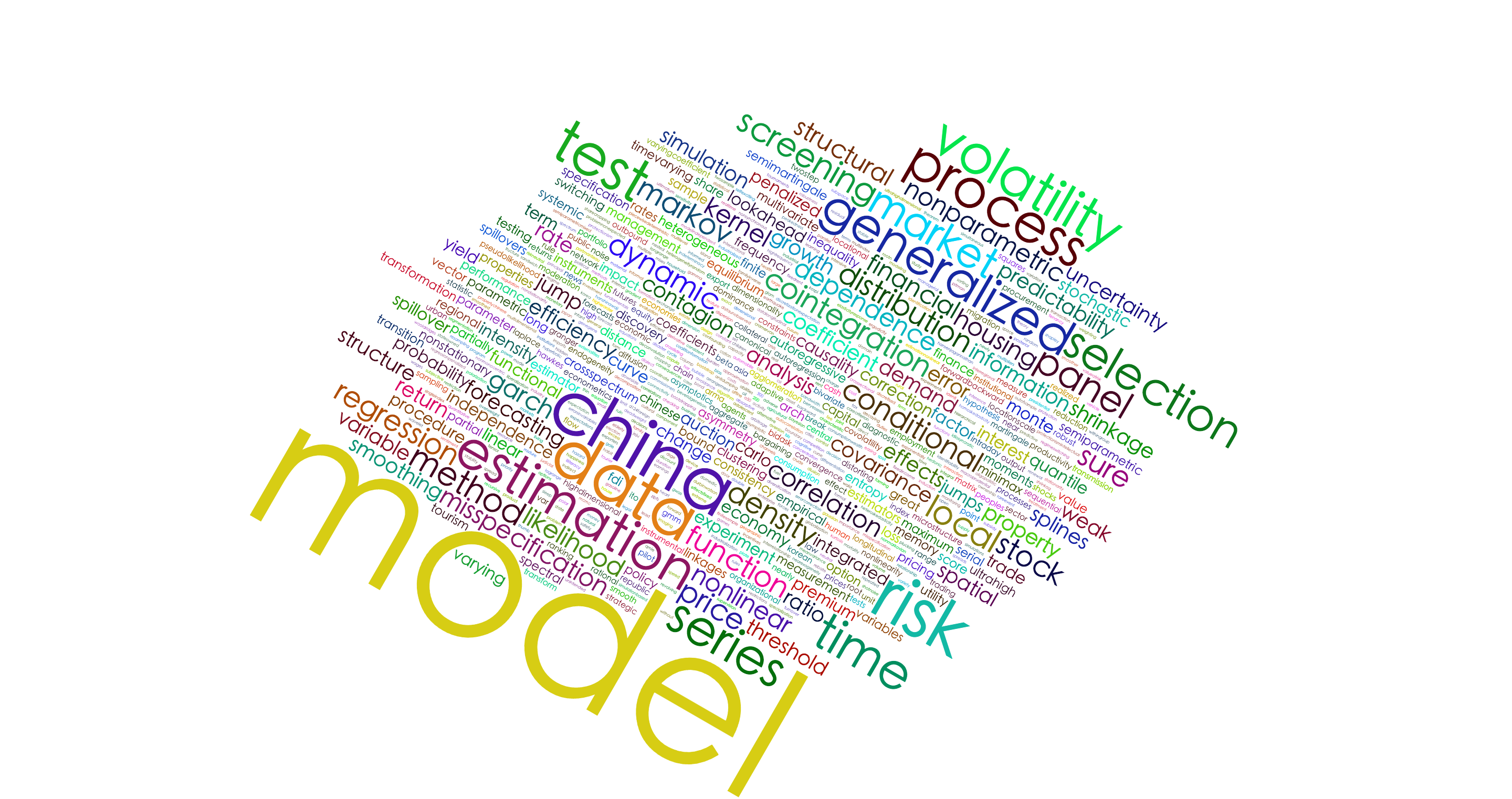
甚至你可以自定义词云的形状:
1 2
| figPath = system.file("examples/t.png",package = "wordcloud2") wordcloud2(demoFreq, figPath = figPath, size = 1.5,color = "skyblue")
|

2.3.2 使用letterCloud绘制词云
1
| letterCloud(termFreq, word = "WISE", size = 2)
|

Wordcloud2: http://lchiffon.github.io/2016/06/01/wordcloud2.html
Introdcution to Wordccloud2: http://lchiffon.github.io/2016/06/10/wordcloud.html
WISE Journal: http://121.192.176.75/index.php?ser_id=2
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| ## R version 3.3.0 (2016-05-03) ## Platform: x86_64-apple-darwin13.4.0 (64-bit) ## Running under: OS X 10.11.1 (El Capitan) ## ## locale: ## [1] zh_CN.UTF-8/zh_CN.UTF-8/zh_CN.UTF-8/C/zh_CN.UTF-8/zh_CN.UTF-8 ## ## attached base packages: ## [1] stats graphics grDevices utils datasets methods base ## ## loaded via a namespace (and not attached): ## [1] magrittr_1.5 formatR_1.2.1 tools_3.3.0 htmltools_0.3.5 ## [5] yaml_2.1.13 Rcpp_0.12.5 stringi_1.0-1 rmarkdown_0.8 ## [9] knitr_1.12.3 stringr_1.0.0 digest_0.6.9 evaluate_0.8
|
