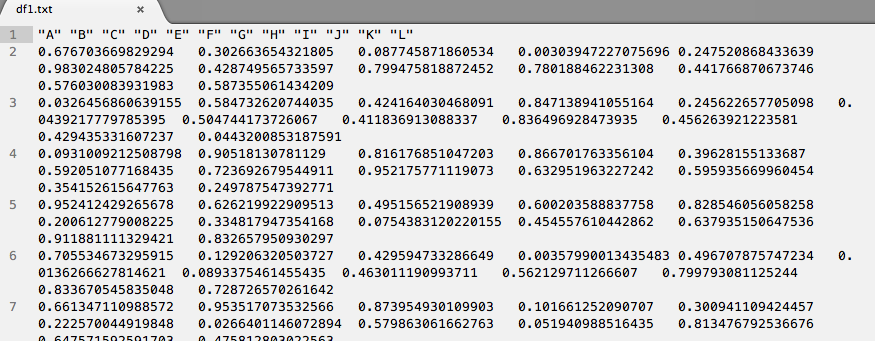
## A B C D E F
## 1: 0.67670367 0.3026637 0.08774587 0.003039472 0.24752087 0.98302481
## 2: 0.03264569 0.5847326 0.42416403 0.847138941 0.24562266 0.04392178
## 3: 0.09310092 0.9051813 0.81617685 0.866701763 0.39628155 0.59205108
## 4: 0.95241243 0.6262199 0.49515652 0.600203589 0.82854606 0.20061278
## 5: 0.70553467 0.1292063 0.42959473 0.003579900 0.49670788 0.01362666
## 6: 0.66134711 0.9535171 0.87395493 0.101661252 0.30094111 0.22257004
## 7: 0.55672622 0.8943379 0.25373346 0.173713098 0.20480512 0.43330278
## 8: 0.44255077 0.4695400 0.22368835 0.504668399 0.05181082 0.20466480
## 9: 0.59814106 0.8319473 0.36690913 0.792975662 0.27411663 0.02809154
## 10: 0.97473503 0.7775101 0.88166877 0.753166205 0.70018055 0.23151788
## G H I J K L
## 1: 0.42874957 0.79947582 0.78018846 0.4417669 0.57603008 0.58735506
## 2: 0.50474417 0.41183691 0.83649693 0.4562639 0.42943533 0.04432009
## 3: 0.72369268 0.95217577 0.63295196 0.5959357 0.35415262 0.24978755
## 4: 0.33481795 0.07543831 0.45455761 0.6379352 0.91188111 0.83265795
## 5: 0.08933755 0.46301119 0.56212971 0.7997931 0.83367055 0.72872657
## 6: 0.02664011 0.57986306 0.05194099 0.8134768 0.64757159 0.47581280
## 7: 0.32301409 0.30541714 0.58960042 0.5959014 0.91273150 0.92101453
## 8: 0.01953665 0.15046710 0.30098137 0.6269210 0.59301203 0.60332790
## 9: 0.80829949 0.50337487 0.85286500 0.4667048 0.34482590 0.45941051
## 10: 0.26011167 0.74538236 0.34376219 0.3313794 0.03101849 0.39811192